| CS418/CS938 Advanced
Topics in
Algorithms and Complexity Computational Learning Theory (Term 1 - 2022/23) Instructor: Igor Carboni Oliveira (igor.oliveira@warwick.ac.uk). Teaching Assistant: Martin Costa (martin.costa@warwick.ac.uk). * General information about this module can be found on the catalogue. The information on this page is specific to the module offered in Term 1 (2022/23). |
 |
Online Resources
Lectures and Assignments (Warwick Account)
Zulip Forum - The preferred place to discuss all things related to this module. An invite link is available here.
Anonymous Feedback Form - Please feel free to submit anonymous suggestions, requests, etc. about the content and delivery of this module.
Overview
What is learning? Can machines make correct predictions based on past observations? Is it possible to identify complex patterns in data?
This module offers an introduction to computational learning theory, a discipline that investigates such questions from the perspective of theoretical computer science. We will formulate precise mathematical models that enable a rigorous study of learning problems and learning algorithms, with a particular focus on the computational efficiency of learning.
Prerequisites
You should be comfortable with reading and writing mathematical proofs, and with elementary notions from discrete probability (probability spaces, events, etc.). This module is only suitable for students familiar with the core material from CS260 (Algorithms) and CS301 (Complexity of Algorithms), such as asymptotic notation, reductions, and NP-hardness. If you're interested in this module but are unsure about your background, please contact the instructor.
List of Topics (Tentative)
A brief introduction to computational learning theory: basic notions and motivation.
Boolean functions and concrete computational models (decision trees, DNFs, threshold circuits, general Boolean circuits).
The online mistake-bound learning model.
Exact learning with membership and equivalence queries.
The Probably Approximately Correct (PAC) learning model.
Occam's Razor and learning by finding a consistent hypothesis. Connections to the P vs NP problem.
Learning algorithms and reductions between learning problems.
VC dimension theory. The amount of data sufficient for learning and computational efficiency.
Boosting algorithms. Converting a weak learner into a strong learner.
Learning in the presence of noise and errors. The statistical query learning model.
Limits of efficient learnability. Connections to cryptography.
Kolmogorov complexity and learning theory.
Connections between learning algorithms, logic, and propositional proofs.
Depending on our progress and interest from the students, we might have lectures given by external speakers on more advanced topics and research questions (e.g., quantum learning algorithms, privacy and learning algorithms, recent developments in learning theory, etc.).
Assessment
There will be three homework assignments, with each of them accounting for 10% of the final grade.
An exam corresponding to the remaining 70% of the grade is currently required due to departmental and university regulations. This exam will test your basic understanding of the material. It will not cover advanced topics presented by the lecturer or by external speakers. A practice exam will be made available towards the end of the module.
References
Lecture notes will be available for most topics covered in class, with links to relevant articles provided in due course. We will follow in part the textbook:
An Introduction to Computational Learning Theory. Umesh Vazirani and Michael Kearns, MIT Press, 1994. (You can access the e-Book via Warwick Library.)
Similar modules:
Varun Kanade (Oxford University): http://www.cs.ox.ac.uk/people/varun.kanade/teaching/CLT-HT-TT2021/
Rocco Servedio (Columbia University): http://www.cs.columbia.edu/~cs4252/
Siu On Chan (The Chinese University of Hong Kong): https://www.cse.cuhk.edu.hk/~siuon/csci4230/
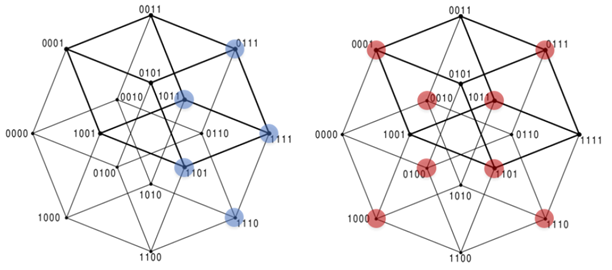
Figure 1. The representation of two Boolean functions as subsets of the 4-dimensional hypercube. While there exist computationally efficient learning algorithms for several classes of Boolean functions, it is believed that such algorithms do not exist for many important learning tasks.