UNIX and Linux Design and Organisation
Overview
The Kernel and Shell
Files
Networks
Technical Basics
Bits,
Bytes, Words and Characters
ASCII
Characters
How to
get Linux
Summary
Bits, Bytes, Words and Characters
Data inside a computer is stored as a sequence of binary digits. Each such digit is called a bit. Exactly how bits are stored does not concern us here, but several different methods can be used depending where on the computer system the data is required. Bits are grouped together in groups of (usually) 8 to form a byte. Bytes are then grouped in 2s, 4s or 8s to form words, the number of bytes in a word depending on the machine being used.
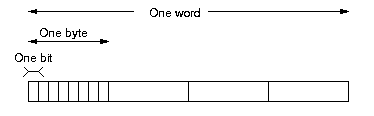 A 4-byte
word.
A 4-byte
word.
It is rarely necessary to enquire what individual bits are stored on a computer. Normally, the byte is regarded as the most basic unit of storage on a machine. Since a byte contains 256 permutations of eight binary digits, a byte can represent any number between 0 and 255 inclusive (or between -128 and +127, or other such ranges).
Just as with a typewriter, communication with UNIX is character-by-character. Unless you are dealing bit-by-bit with the data stored in the system's memory, it is helpful to think of each byte representing a character, such as the letter 'A' or the symbol '@', since there is a correspondence between characters and the numeric codes (between 0 and 255) that can be stored in a byte. The most common coding scheme used is called ASCII (American Standard Code for Information Interchange), in which codes for the upper-case letters 'A' to 'Z' are 65 to 90, for lower-case letters 'a' to 'z' they are 97 to 122, and for the digits '0' to '9' they are 48 to 57. Other codes are used for other symbols.
In the earlier days of computing, the electronic components were often unreliable, and the final bit in a byte was used as a check digit whose value is determined by a simple calculation from the other seven bits. If one of the other seven bits is changed, the value of the eighth, which is referred to as a parity bit, is also changed. This parity check can then be used to identify bytes whose contents have been accidentally altered.
Parity checking is an unsophisticated form of error detection, and modern equipment seldom uses it, thus allowing 256 character codes to be stored in a single 8-bit byte, rather than just 128. Usually the first 128 match the ASCII character set, and the remaining characters are used for extra symbols, such as currency symbols and accented letters from languages other than English. One such code is known as LATIN-1. For the symbols used in this book these two codings are identical. Other codings do exist, however, perhaps the best known being EBCDIC (Extended Binary Coded Decimal Interchange Code) and the 16-bit Unicode, but for the purposes of this book, we shall assume ASCII is being used.
Note that if you total the number of letters, digits, punctuation marks and other graphics symbols, there are nowhere near 256 of them - some codes relate to non-printing characters. These are characters which, rather than representing a symbol that can be printed on a computer screen, denote other actions that the computer display can perform.